Eclipse — Configuration
1 Introduction
Ce document explique comment configurer correctement Eclipse avant de commencer à travailler sur le projet. Le but des configurations ci-dessous est de standardiser la représentation des fichiers source Java créés par Eclipse, d'une part pour faciliter le travail en groupe et d'autre part pour faciliter la correction des projets.
Notez bien que ces configurations sont obligatoires et que toute personne tentant de rendre un projet écrit dans une version d'Eclipse configurée différemment s'expose à voir son rendu refusé.
Pour comprendre le but de ces configurations, il faut savoir que les fichiers source Java sont des fichiers textuels. Cela signifie qu'ils ne possèdent quasiment aucune structure et consistent en une simple suite de caractères. Malheureusement, pour des raisons historiques, il n'existe pas de format universellement accepté pour représenter de tels fichiers textuels. Chaque système d'exploitation (OS X, Windows, Linux, etc.) utilise des conventions qui lui sont propres, par exemple pour représenter les caractères accentués ou les fins de lignes.
Par exemple, le caractère é (e aigü) est généralement représenté par l'octet 142 sur OS X (avec l'encodage Mac Roman), par l'octet 233 sur Windows (avec l'encodage Windows-1252) et par la suite de deux octets 195 et 166 sur Linux (avec l'encodage UTF-8).
Cela peut poser problème lorsque plusieurs personnes travaillent sur un même projet, car chacune utilisera les conventions propres à son système, et les fichiers écrits par l'une ne seront que difficilement lisibles par l'autre. Il en va de même lorsqu'un correcteur essaie de lire un fichier écrit par une personne travaillant sur un autre système que le sien.
2 Marche à suivre
Trois aspects des fichiers textuels sont à configurer, à savoir : l'encodage des caractères, la terminaison des lignes et la gestion du caractère de tabulation. Les sections ci-dessous décrivent les configurations à effectuer et expliquent rapidement leur but.
2.1 Encodage des caractères
2.1.1 Procédure
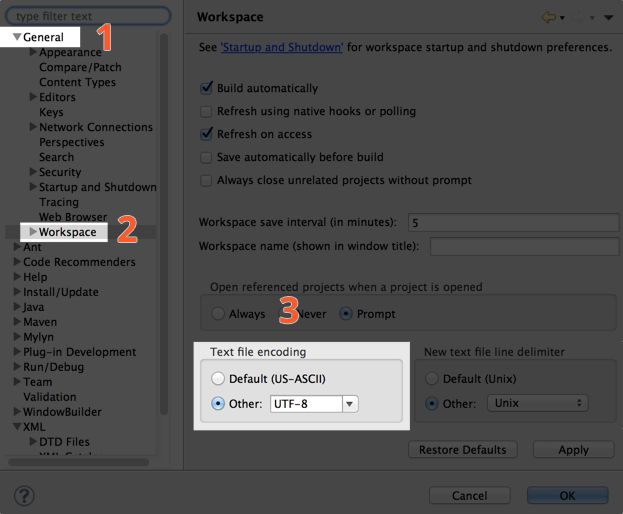
Ouvrez les préférences d'Eclipse, déroulez la section nommée General puis cliquez sur Workspace pour avoir accès à la configuration de l'espace de travail. Changez le réglage pour Text file encoding en cliquant sur Other et en sélectionnant UTF-8 dans le menu déroulant.
2.1.2 Justification
UTF-8 est un encodage du jeu de caractères Unicode, dont le but est de devenir l'encodage standard pour tous les caractères existants dans le monde. Il est disponible sur tous les systèmes d'exploitation modernes, raison pour laquelle nous l'utiliserons pour ce projet. Pour plus de détails, reportez-vous aux références ci-dessous.
2.1.3 Références
- Le minimum absolu que tout développeur doit absolument, positivement savoir sur Unicode et les jeux de caractères (aucune excuse !) de Joël Spolsky (version traduite en français de l'article suivant)
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) de Joel Spolsky (en anglais)
2.2 Terminaison des lignes
2.2.1 Procédure
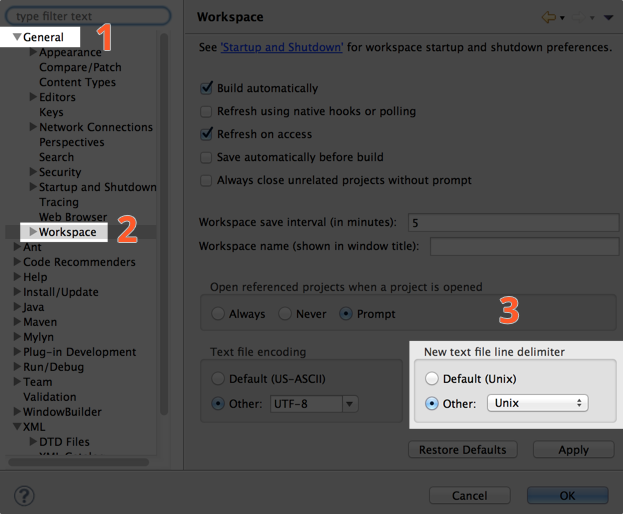
Toujours dans les réglages liés à l'espace de travail, changez le réglage pour New text file line delimiter en cliquant sur Other et en sélectionnant Unix dans le menu déroulant.
2.2.2 Justification
Toujours pour des raisons historiques, les différents systèmes d'exploitation ont chacun leur manière de représenter les fins de ligne : Windows utilise la séquence de deux octets 13 et 10, Mac OS utilise l'octet 10 (depuis la version 10.0, avant il utilisait 13) et les systèmes Unix comme Linux utilisent 10.
2.2.3 Références
- Newline sur Wikipedia (en anglais, plus complet que la version française)
- Fin de ligne sur Wikipedia
2.3 Tabulations
2.3.1 Procédure
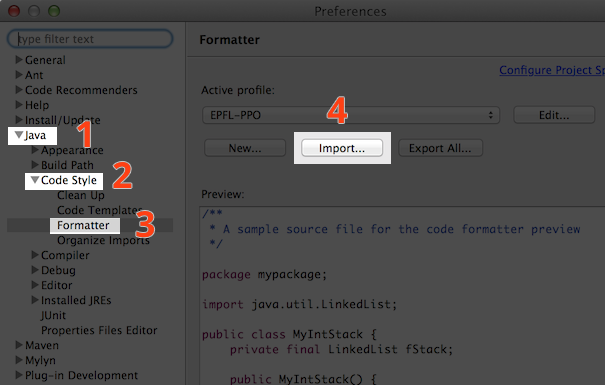
Téléchargez le fichier EPFL-PPO.xml que nous mettons à votre disposition puis importez-le dans Eclipse. Pour ce faire, toujours dans les préférences, ouvrez la section nommée Java, puis Code style puis Formatter. Cliquez sur Import… et désignez le fichier que vous venez de télécharger.
2.3.2 Justification
Pour faciliter leur lecture, les programmes informatiques sont généralement indentés, c'est-à-dire que des espaces sont placées au début des lignes afin de refléter la structure du programme. Ces espaces peuvent être simplement représentées par une séquence de caractères d'espacement, encodés par l'octet 32 en UTF-8. Toutefois, une autre solution est souvent employée : le caractère tabulation, encodé par l'octet 9, qui représente plusieurs espaces. Malheureusement, le nombre exact d'espaces représenté par le caractère tabulation varie de système en système, et souvent même d'éditeur en éditeur.
Dès lors, il est préférable d'éviter totalement l'utilisation du caractère tabulation dans les programmes. C'est ce que fait le fichier donné plus haut.
2.3.3 Références
- Tab characters sur Wikipedia (une section de l'article Tab key, indisponible en français)